Introduction
Your project has been going on for eight months, and each milestone has been met so far. Final test has not occurred yet, but you feel that the product will be ready.
Quick Test
Before each statement below, ask the question, “Am I on track to deliver by the final deadline?”
Fact 1. The last component tested worked and only had three defects. These were repaired.
Fact 2. You were unaware that 10 out of the other 20 components had on average five severe defects, and after repair they were never thoroughly retested.
Fact 3. You were unaware that all the test cases only cover 70 percent of the code base, leaving 30 percent of the code unexecuted.
Fact 4. The peer review of each requirements backlog found on average 40 defects. You are unsure of how thoroughly the defects were fixed.
So, are you ready to ship if the testing phase completes?
Looking at Test and Peer Review Data
If you were unaware of the four stated facts, then you might decide to proceed because everything looks great. However, if you have visibility into the project from a quality perspective throughout, then you might decide to mitigate the risks highlighted in the four statements above.
For example, how will the first 10 components that were not retested correctly perform? How will the 30 percent of unexecuted code perform when released? If the requirements had numerous defects in them, were they corrected, did they capture the users’ need?
Would you ship this system? (Peer Review Analysis)
Here is some real data of a client that was experiencing a 70 percent project rework rate. A look under the hood into the code using inspections (team peer reviews) provided some clues. Write down your conclusions before you read on.
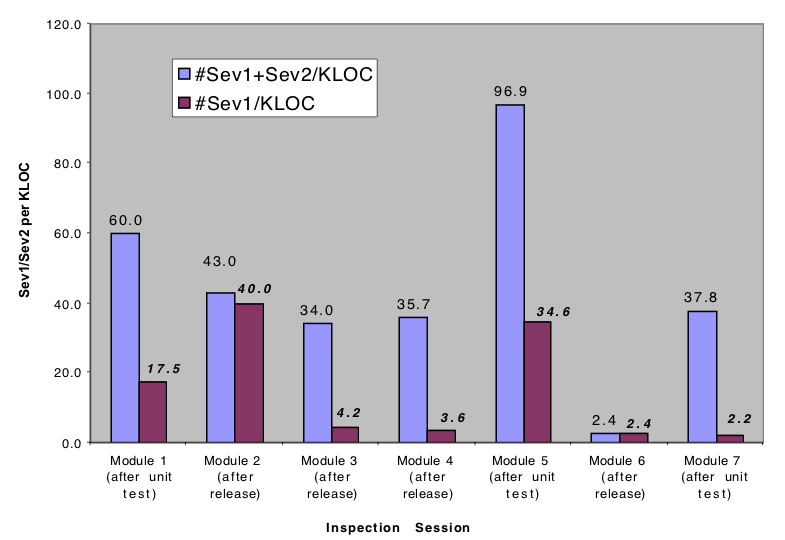
Figure 1 – Number of Severity 1 and 2 defects per unit of size remaining in code after test and release.
Click on the graph to enlarge.
The data in Figure 1 shows the number of Severity 1 and Severity 2 defects found in seven code modules selected from the company’s product suite. Some modules had already been released to customers; the remainder had been through unit test and were about to enter system testing. To understand the 70 percent rework rate, each module underwent inspection (peer review) by a team of five people. The peer review data established a baseline picture of the current rework problem.
From this small amount of data, it was obvious that code after unit test and code released to the field was very poor. These defects – and ones similar to these in other areas of their code base – were the primary source of their rework problem.
Further analysis of the data showed that many defects were situations where the program did not check for invalid input such as empty data structures and null pointers. Investigation showed that the code sample labeled “Module 6 (after release)” had few defects because the author had built-in checks for incoming defective data. From these observations, the team created a checklist to remind developers of these coding practices.
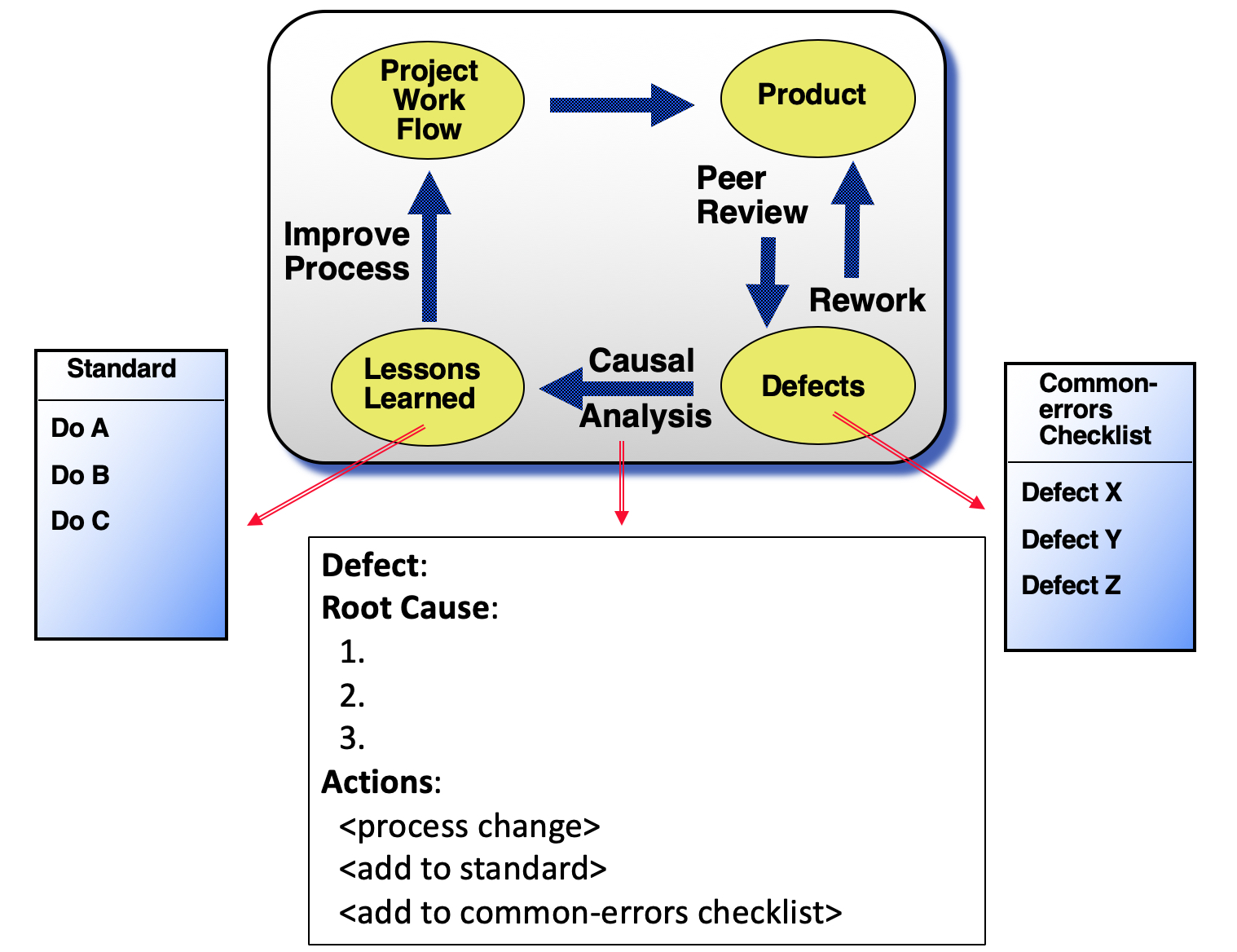
The analysis can be summarized as:
Observation: The majority of defects escape to the customer.
Cause:
– Code does not check for invalid inputs, such as empty data structures and null pointers.
– Peer reviews and testing are ad-hoc based on each developer’s preference.
Actions:
– Create a 1-page checklist to remind developers of good coding practices.
– Peer review all new code. Peer review the most buggy legacy code.
– Define acceptance criteria when requirements are written.
Other examples of verification data analysis
There are many ways to analyze verification (peer review and test) data. Here are some examples.
Simple analysis
1. Test defect open and close rate (Test Analysis)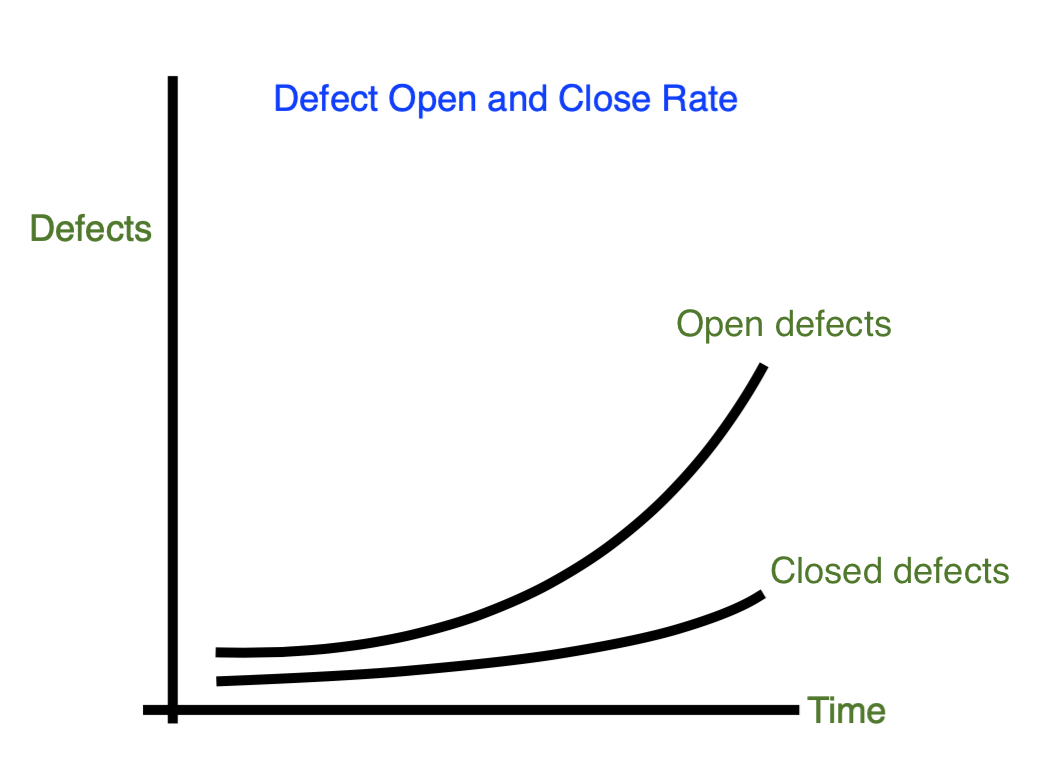
Analysis
Observation: Gap widening and deadline looming.
Cause:
– No definition of “done” for code (e.g., peer reviewed, meets acceptance criteria, version controlled).
– Code goes untested to testers.
Action:
– Define “done.”
– Peer review code.
– Define acceptance criteria.
2. Defect density trend for each work product over time (Peer Review and Test Analysis)
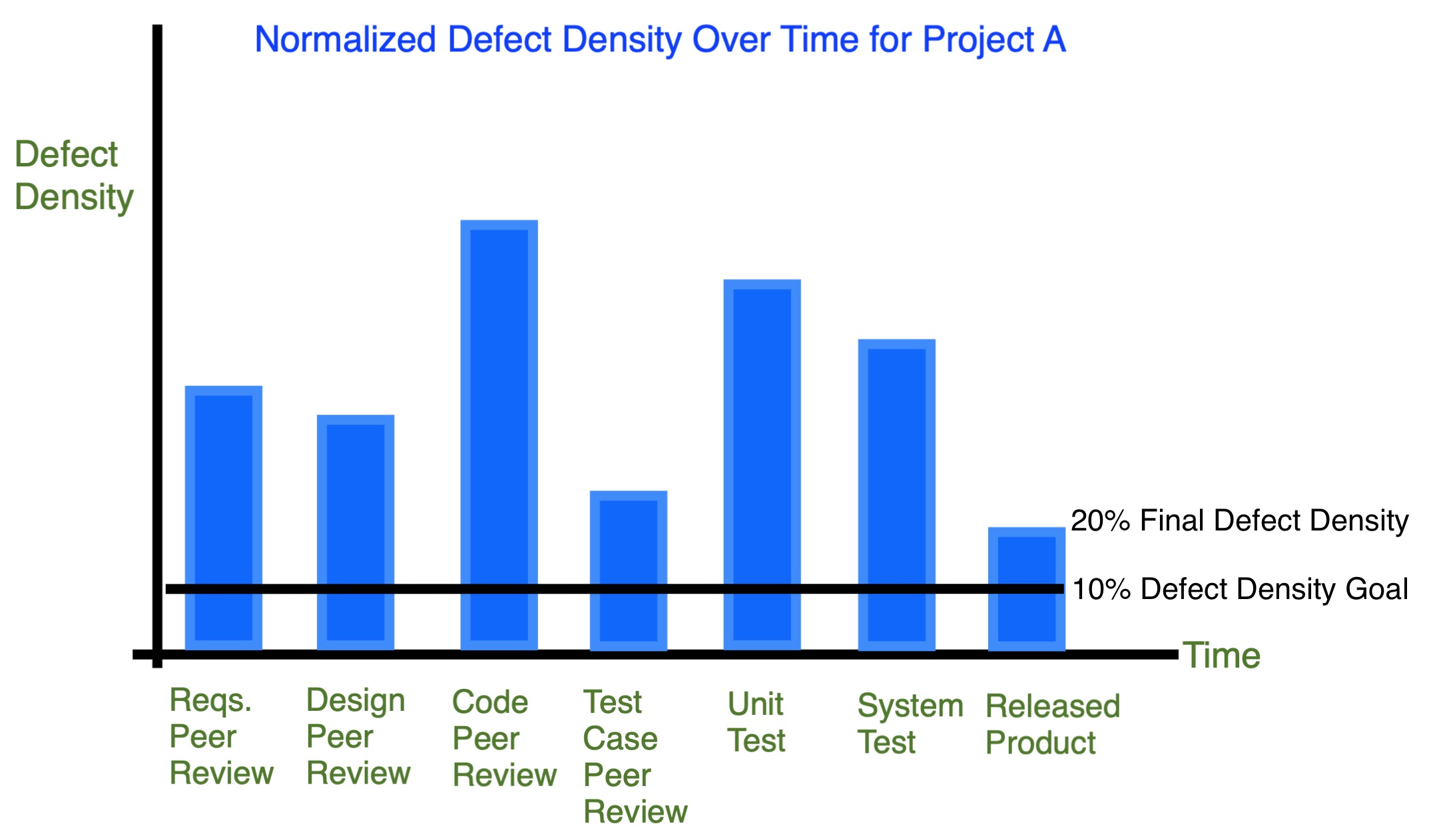
Analysis
Observation: Many defects escape into the released product.
Cause: No check of fixes for initial peer review and test defects.
Action: Define defect threshold for when to perform a second peer review and assign a person to check the repairs.
3. Defects found by peer review and test, before and after release (Peer Review and Test Analysis)
Example 1: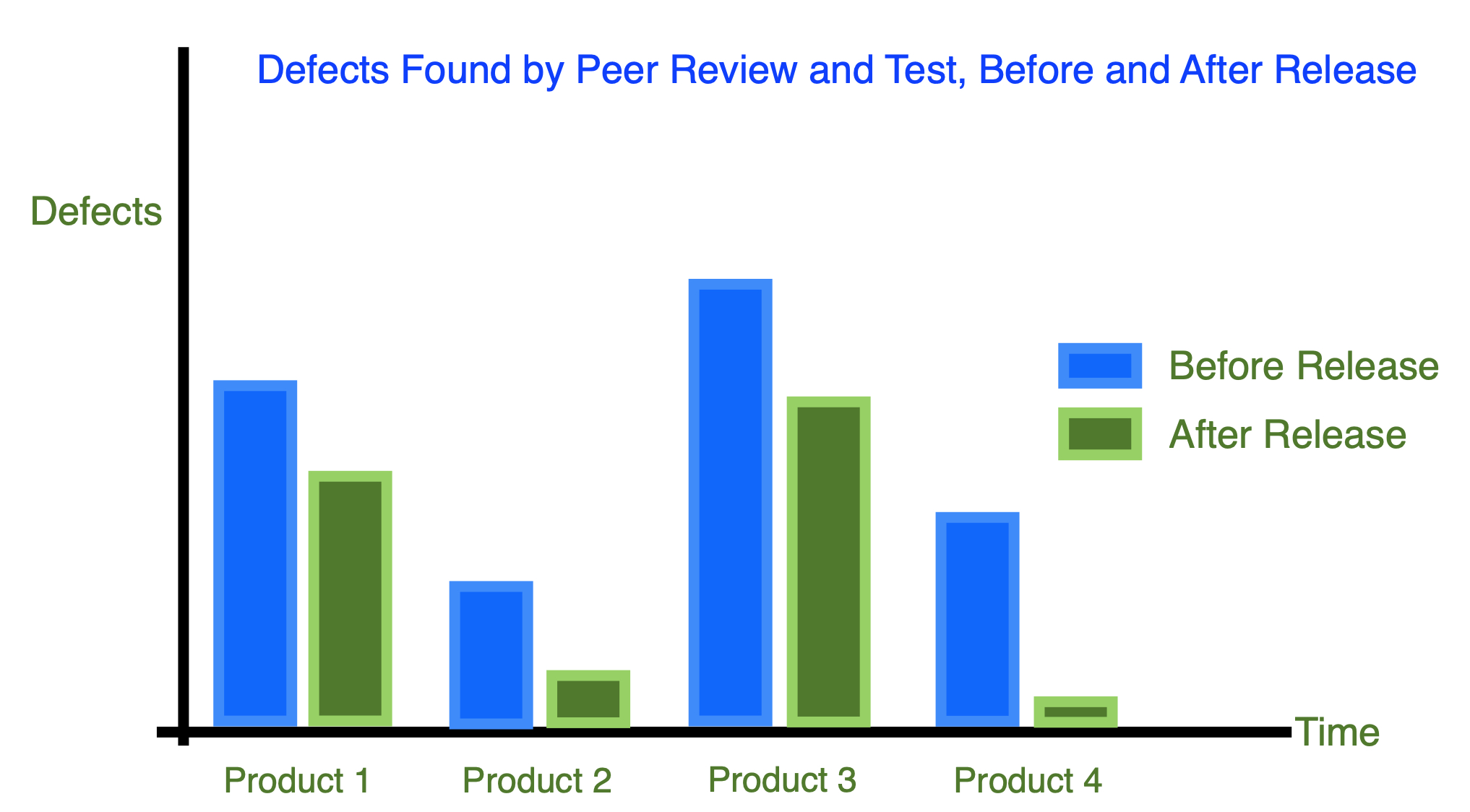
Analysis
Observation: Inconsistent percentage of defects found before each release.
Cause: There is no standard set of practices across teams to find defects.
Action: Define minimal testing and peer review steps before release. Learn from Product 4.
Example 2:
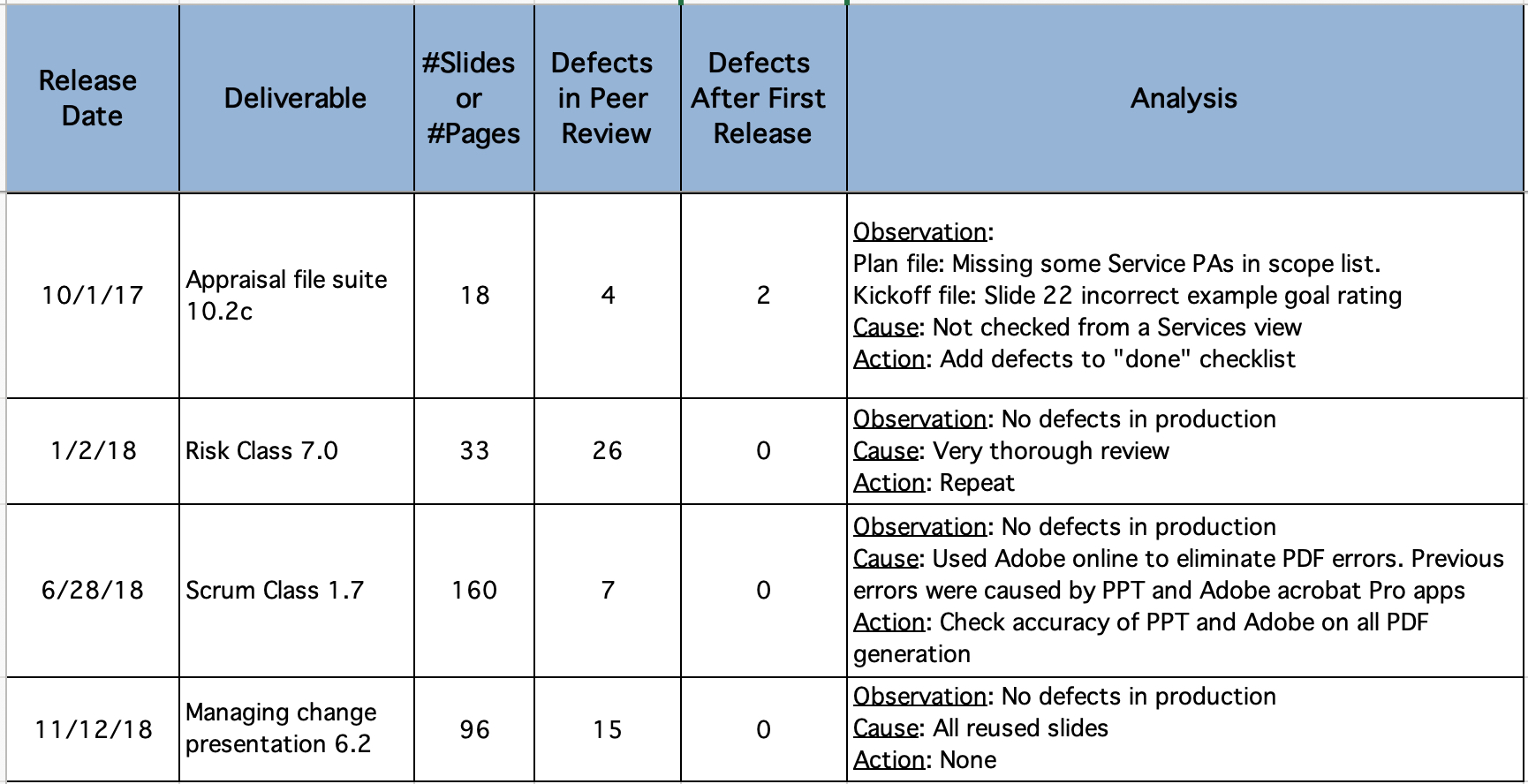
4. Number of Test cycles needed before release (Test Analysis)
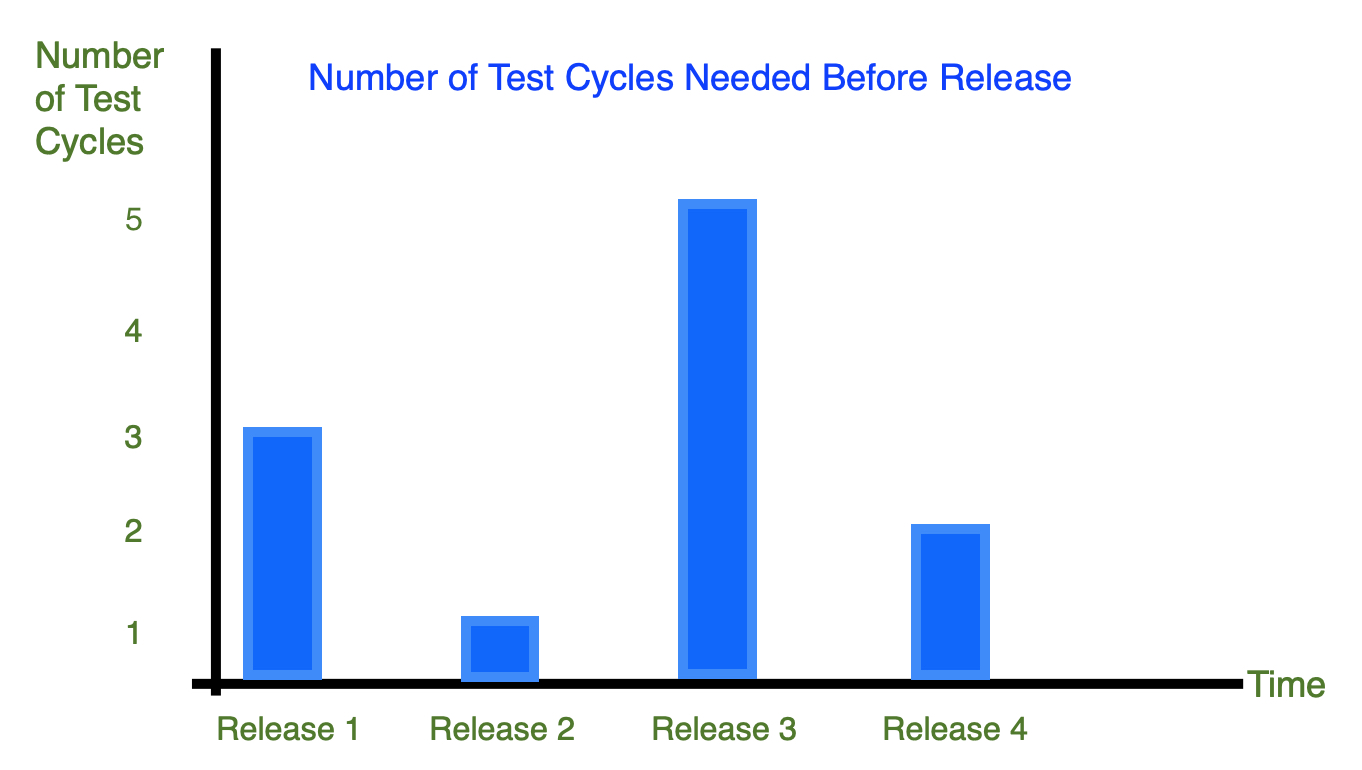
Analysis
Observation: Number of needed test cycles (and therefore final deadline) is unpredictable.
Cause: There is no consistent set of verification practices used.
Action:
– Define verification practices for each release.
– Check that acceptance criteria are defined and developers work towards this before final test.
5. Record the most common and severe work product defects into a checklist and determine the root causes for selected ones (Peer Review Analysis)
6. Team peer review score (Peer Review Analysis)
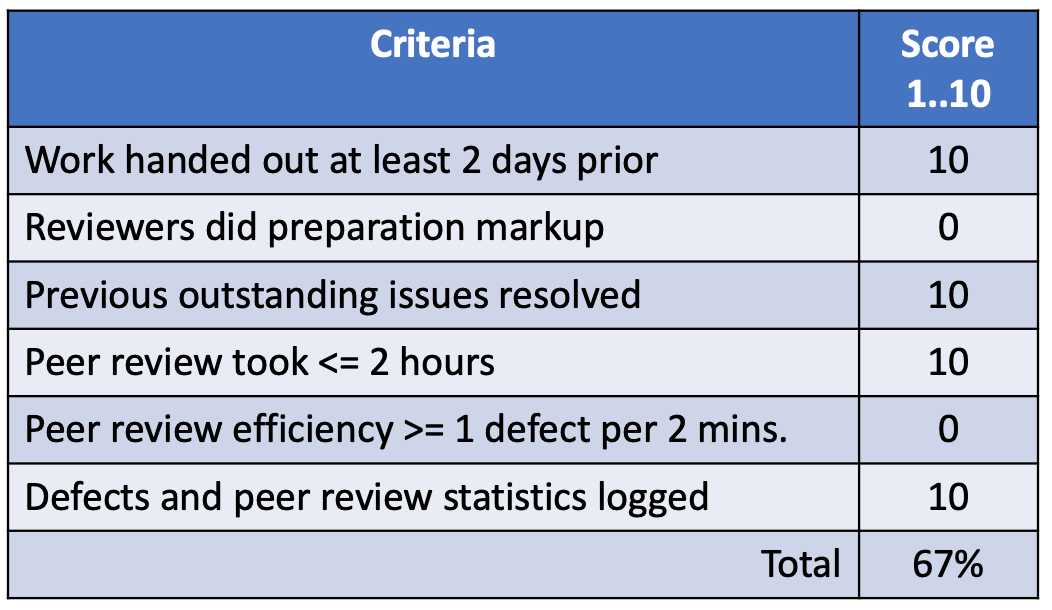
Analysis
Observation: No one performed preparation before the peer review, reducing the number of defects found and the efficiency of the meeting.
Cause: A release of another project took people’s time.
Action:
– Allocate 1 week for preparation.
– Check before the peer review that preparation is done. If not, postpone the peer review and flag the specific coding milestone as incomplete.
More advanced analysis
7. Defects by type (Peer Review and Test Analysis)

Observation: Requirements and code defects account for approximately 80 percent of the problems.
Cause: No thorough review or analysis of requirements or code.
Action:
– Codify requirements and coding defects into a checklist.
– Train teams on checklist and monitor use.
8. Verification efficiency — total effort needed to find each defect for test vs. peer reviews (Peer Review and Test Analysis)
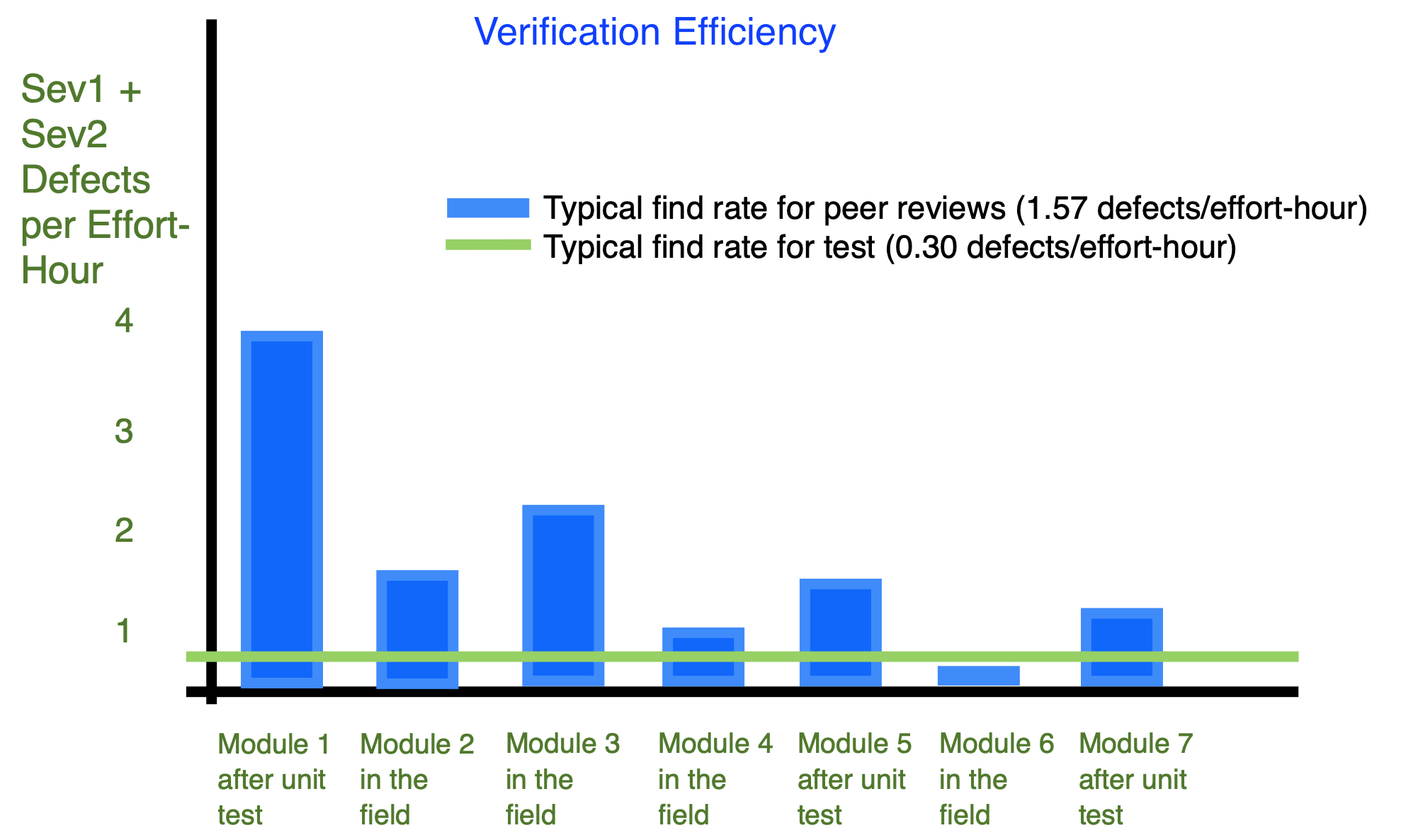
Analysis
Observation:
– Many defects are found after unit test and after release.
– Defects are found on average 5x faster by peer reviews (ratio 1.57:0.30).
Cause:
– Inconsistent use of peer reviews and test practices. No criteria for good code.
Action:
– Adopt per reviews for all critical and risky code (initially).
– Define minimum coding practices (e.g., memory leaks, parameter passing, error flag check).
Conclusion
Your project probably has numerous opportunities to count defect data along the way. Take a look at some of it and see what it is telling you.
If you would like help on your verification practices, contact us.
[Forward this email to your boss! Subject: Here’s a cool tip for you] Quick LinkThanks to Jeff and Mary for the thorough article review.
References to CMMI V2.0 practices
The practices below are from the CMMI model that refer to the analysis of peer review and test data. They are the most miserably performed practices on earth (:<).
The intent is to use peer review and test data to provide an ongoing quality view into a project. Analysis means to derive some conclusions about the data, or as the Merriam-Webster dictionary says, “A detailed examination of anything complex in order to understand its nature or to determine its essential features: a thorough study.”
Hopefully the article will provide some ideas. A combination of the examples above would address these practices.
CMMI V2.0
PR 3.1: Analyze results and data from peer reviews.
VV 3.2: Analyze and communicate verification and validation results.

{kind=link}
{kind=link}
{kind=link}
{kind=link}